Stories



-
![مونديال 2026]()
مونديال 2026
RT STORIES
سيناريوهات التأهل.. الفراعنة يضعون قدما في دور الـ32 قبل موقعة إيران الحاسمة
![سيناريوهات التأهل.. الفراعنة يضعون قدما في دور الـ32 قبل موقعة إيران الحاسمة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
تاريخ يُكتب.. البوسنة أول المتأهلين كأفضل ثالث إلى دور الـ32
![تاريخ يُكتب.. البوسنة أول المتأهلين كأفضل ثالث إلى دور الـ32]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رحلة المكسيك وجنوب إفريقيا في الأدوار الإقصائية مواعيد وأماكن المواجهات تتحدد
![رحلة المكسيك وجنوب إفريقيا في الأدوار الإقصائية مواعيد وأماكن المواجهات تتحدد]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
جنوب إفريقيا تصنع المفاجأة وتخطف بطاقة التأهل من كوريا الجنوبية في مونديال 2026
![جنوب إفريقيا تصنع المفاجأة وتخطف بطاقة التأهل من كوريا الجنوبية في مونديال 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
المكسيك تحقق العلامة الكاملة بدور المجموعات لأول مرة.. والتشيك تودع المونديال
![المكسيك تحقق العلامة الكاملة بدور المجموعات لأول مرة.. والتشيك تودع المونديال]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"عجوز على عكازين".. شقيقة رونالدو تدافع عنه بطريقة غير متوقعة وتثير الجدل
!["عجوز على عكازين".. شقيقة رونالدو تدافع عنه بطريقة غير متوقعة وتثير الجدل]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
نبض اليوم الـ15 من مونديال 2026.. العد التنازلي للأدوار الإقصائية
![نبض اليوم الـ15 من مونديال 2026.. العد التنازلي للأدوار الإقصائية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
المغرب ينتفض أمام هايتي برباعية ويبلغ دور الـ32 في كأس العالم
![المغرب ينتفض أمام هايتي برباعية ويبلغ دور الـ32 في كأس العالم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
قطر تودع نهائيات كأس العالم بالخسارة أمام البوسنة بثلاثية
![قطر تودع نهائيات كأس العالم بالخسارة أمام البوسنة بثلاثية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
كيف تحسم بطاقات التأهل إلى دور الـ32 في كأس العالم 2026؟
![كيف تحسم بطاقات التأهل إلى دور الـ32 في كأس العالم 2026؟]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
منتخب السنغال يتلقى ضربة مؤثرة قبل مواجهة العراق
![منتخب السنغال يتلقى ضربة مؤثرة قبل مواجهة العراق]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مشجع الكونغو الشهير يظهر لأول مرة في كأس العالم 2026
![مشجع الكونغو الشهير يظهر لأول مرة في كأس العالم 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الأرجنتين تستعد لاحتفال غير تقليدي بعيد ميلاد ميسي الـ39
![الأرجنتين تستعد لاحتفال غير تقليدي بعيد ميلاد ميسي الـ39]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
جدل المليارات يلاحق مونديال 2026.. و"فيفا" تكشف حقيقة العوائد الإعلانية
![جدل المليارات يلاحق مونديال 2026.. و"فيفا" تكشف حقيقة العوائد الإعلانية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مدرب غانا بعد التعادل مع نجلترا: "حكم الـVAR ذهبت لشرب القهوة!"
![مدرب غانا بعد التعادل مع نجلترا: "حكم الـVAR ذهبت لشرب القهوة!"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجولة الثالثة في كأس العالم 2026… "أسبوع الحسم" للمنتخبات العربية
![الجولة الثالثة في كأس العالم 2026… "أسبوع الحسم" للمنتخبات العربية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بعد نهاية الجولة الثانية من مونديال 2026.. ماهي المنتخبات المتأهلة لدو الـ32 حتى الآن؟!
![بعد نهاية الجولة الثانية من مونديال 2026.. ماهي المنتخبات المتأهلة لدو الـ32 حتى الآن؟!]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مونيوز يقود كولومبيا لتأهل مستحق إلى دور الـ32 من مونديال 2026
![مونيوز يقود كولومبيا لتأهل مستحق إلى دور الـ32 من مونديال 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
أسطورة إيطاليا كانافارو يفاجئ الجميع بطلب مثير لرونالدو بعد خماسية البرتغال
![أسطورة إيطاليا كانافارو يفاجئ الجميع بطلب مثير لرونالدو بعد خماسية البرتغال]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
كرواتيا تنعش آمالها وتقصي بنما من كأس العالم 2026
![كرواتيا تنعش آمالها وتقصي بنما من كأس العالم 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
نبض اليوم الـ14 من المونديال.. حسم بطاقات العبور ومواجهات لا تقبل القسمة على اثنين
![نبض اليوم الـ14 من المونديال.. حسم بطاقات العبور ومواجهات لا تقبل القسمة على اثنين]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![مونديال 2026]() مونديال 2026
مونديال 2026
-
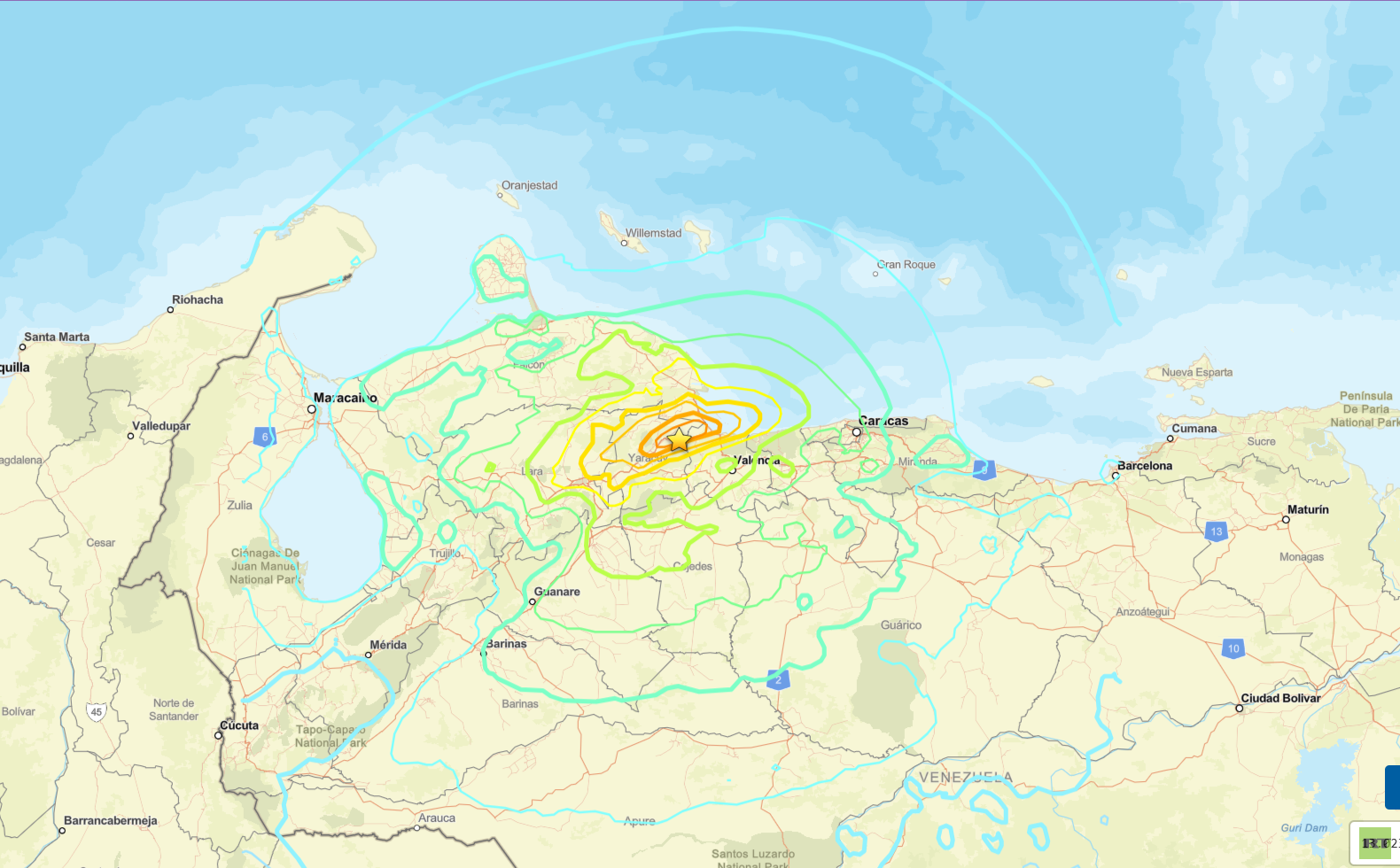
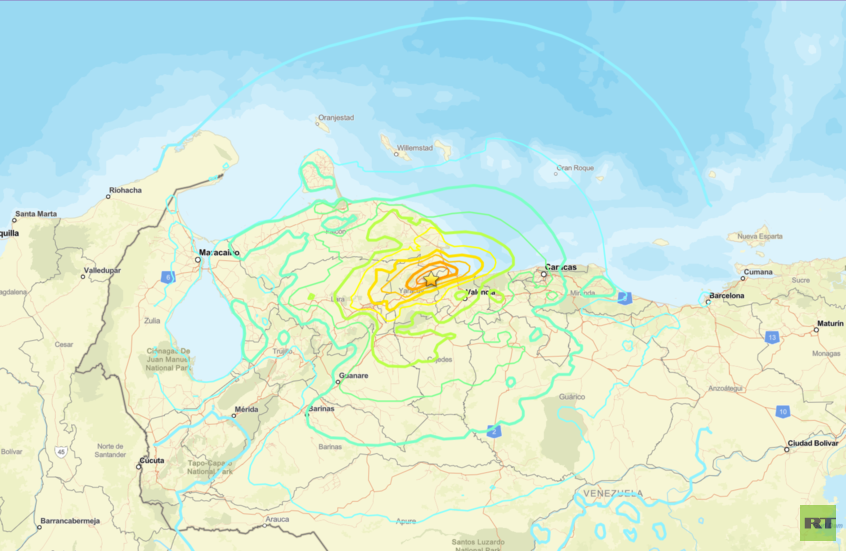
![زلزال فنزويلا]()
زلزال فنزويلا
RT STORIES
فنزويلا تعلن حالة الطوارئ.. عشرات القتلى والجرحى في حصيلة أولية للزلزالين المدمرين (فيديو)
![فنزويلا تعلن حالة الطوارئ.. عشرات القتلى والجرحى في حصيلة أولية للزلزالين المدمرين (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
زلزالان قويان يضربان فنزويلا.. دمار هائل ومخاوف من خسائر بشرية كبيرة (فيديو)
![زلزالان قويان يضربان فنزويلا.. دمار هائل ومخاوف من خسائر بشرية كبيرة (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مادورو من خلف القضاب الأمريكية: لا تتركوا أحداً بمفرده" في وجه زلزال فنزويلا المدمر!
![مادورو من خلف القضاب الأمريكية: لا تتركوا أحداً بمفرده" في وجه زلزال فنزويلا المدمر!]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الخارجية الأمريكية: الولايات المتحدة تستعد لتقديم مساعدات إلى فنزويلا بعد الزلزال
![الخارجية الأمريكية: الولايات المتحدة تستعد لتقديم مساعدات إلى فنزويلا بعد الزلزال]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![زلزال فنزويلا]() زلزال فنزويلا
زلزال فنزويلا
-
![اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات]()
اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات
RT STORIES
إيران تستثمر تصريحات روته وتوجه اتهامات لدولتين أوروبيتين بدعم الحرب ضدها
![إيران تستثمر تصريحات روته وتوجه اتهامات لدولتين أوروبيتين بدعم الحرب ضدها]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الحرس الثوري يحذر السفن من ممرات عبر هرمز تم الإعلان عنها "دون تنسيق مع إيران"
![الحرس الثوري يحذر السفن من ممرات عبر هرمز تم الإعلان عنها "دون تنسيق مع إيران"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مدرسة ميناب.. قد لا يتم التوصل أبدا إلى تحديد المسؤول عن استهدافها خلال الحرب على إيران
![مدرسة ميناب.. قد لا يتم التوصل أبدا إلى تحديد المسؤول عن استهدافها خلال الحرب على إيران]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"حزب الله" يصدر بيانا بشأن استهداف إسرائيل لمواطنين لبنانيين: نراقب ونرصد الانتهاكات
!["حزب الله" يصدر بيانا بشأن استهداف إسرائيل لمواطنين لبنانيين: نراقب ونرصد الانتهاكات]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
إيطاليا توبخ أمين عام الناتو بسبب تصريحاته حول استخدام القواعد الأمريكية خلال الحرب مع إيران
![إيطاليا توبخ أمين عام الناتو بسبب تصريحاته حول استخدام القواعد الأمريكية خلال الحرب مع إيران]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
روبيو: مفاوضات الفرق الفنية حول إيران ستستمر الأسبوع المقبل
![روبيو: مفاوضات الفرق الفنية حول إيران ستستمر الأسبوع المقبل]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ترامب: إيران تقدم تنازلات كبيرة جدا في مفاوضاتها مع الولايات المتحدة
![ترامب: إيران تقدم تنازلات كبيرة جدا في مفاوضاتها مع الولايات المتحدة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
عراقجي وبن فرحان يبحثان هاتفيا مستجدات المفاوضات الأمريكية الإيرانية والأوضاع الإقليمية
![عراقجي وبن فرحان يبحثان هاتفيا مستجدات المفاوضات الأمريكية الإيرانية والأوضاع الإقليمية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
وسائل إعلام تكشف عن خطط واشنطن لإنفاق 500 مليون دولار من الأصول الإيرانية
![وسائل إعلام تكشف عن خطط واشنطن لإنفاق 500 مليون دولار من الأصول الإيرانية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ترامب: التصويت في الكونغرس لن يؤثر على المفاوضات.. هناك تقدم ممتاز وأداء رائع مع إيران
![ترامب: التصويت في الكونغرس لن يؤثر على المفاوضات.. هناك تقدم ممتاز وأداء رائع مع إيران]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"فوكس نيوز": إدارة ترامب تحتاج إلى 672 مليون دولار لإخراج اليورانيوم من إيران
!["فوكس نيوز": إدارة ترامب تحتاج إلى 672 مليون دولار لإخراج اليورانيوم من إيران]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ترامب: حلفاء الناتو الأوروبيون خذلوا الولايات المتحدة خلال الحرب مع إيران
![ترامب: حلفاء الناتو الأوروبيون خذلوا الولايات المتحدة خلال الحرب مع إيران]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ترامب يهدد بوقف المفاوضات مع إيران
![ترامب يهدد بوقف المفاوضات مع إيران]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ترامب: نغادر إيران الآن وهي دون قدرات صاروخية أو برنامج نووي
![ترامب: نغادر إيران الآن وهي دون قدرات صاروخية أو برنامج نووي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
شهباز شريف: برنامج الصواريخ الباليستية الإيراني لم يكن مطروحا في التفاهمات مع واشنطن
![شهباز شريف: برنامج الصواريخ الباليستية الإيراني لم يكن مطروحا في التفاهمات مع واشنطن]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات]() اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات
اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات
-
![العملية العسكرية الروسية في أوكرانيا]()
العملية العسكرية الروسية في أوكرانيا
RT STORIES
تدمير مسيرتين متجهتين إلى موسكو وحريق في مستودع نفط بعد سقوط مسيرة في جنوب روسيا
![تدمير مسيرتين متجهتين إلى موسكو وحريق في مستودع نفط بعد سقوط مسيرة في جنوب روسيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مدفيديف: أعددنا إجراءات مضادة في حال مصادرة أصولنا في الخارج
![مدفيديف: أعددنا إجراءات مضادة في حال مصادرة أصولنا في الخارج]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مدفيديف: الغرب لا يريد حربا نووية ونخبه تتمنى هزيمة روسيا وتفككها
![مدفيديف: الغرب لا يريد حربا نووية ونخبه تتمنى هزيمة روسيا وتفككها]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بعثة روسيا لدى الأمم المتحدة: عواصم أوروبية متواطئة في صنع مسيرات تستخدمها كييف لقتل الأطفال الروس
![بعثة روسيا لدى الأمم المتحدة: عواصم أوروبية متواطئة في صنع مسيرات تستخدمها كييف لقتل الأطفال الروس]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"الخماسية الأوروبية" تسعى لتعميق الشراكة بين الناتو وأوكرانيا وتقريبها من الحلف
!["الخماسية الأوروبية" تسعى لتعميق الشراكة بين الناتو وأوكرانيا وتقريبها من الحلف]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بوليانسكي: أوروبا وصلت إلى نقطة خطيرة في مواجهتها لروسيا
![بوليانسكي: أوروبا وصلت إلى نقطة خطيرة في مواجهتها لروسيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
القوات الروسية تخترق الدفاعات الأوكرانية وتتقدم بعمق 15 كيلومترا داخل مقاطعة سومي الحدودية
![القوات الروسية تخترق الدفاعات الأوكرانية وتتقدم بعمق 15 كيلومترا داخل مقاطعة سومي الحدودية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
لافروف: نشر قوات أوروبية في أوكرانيا سيعيد بناء جدار برلين من جديد و إلى الأبد
![لافروف: نشر قوات أوروبية في أوكرانيا سيعيد بناء جدار برلين من جديد و إلى الأبد]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مدفيديف: أوكرانيا بلا سلطة ونظام كييف غير مهتم بالاتفاق مع روسيا
![مدفيديف: أوكرانيا بلا سلطة ونظام كييف غير مهتم بالاتفاق مع روسيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الدفاع الروسية: إسقاط 245 طائرة مسيرة أوكرانية فوق مناطق روسية والبحر الأسود
![الدفاع الروسية: إسقاط 245 طائرة مسيرة أوكرانية فوق مناطق روسية والبحر الأسود]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
قنابل حائمة تستهدف مواقع القوات الأوكرانية
![قنابل حائمة تستهدف مواقع القوات الأوكرانية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الدفاع الروسية تعلن تحرير بلدة جديدة شمال أوكرانيا
![الدفاع الروسية تعلن تحرير بلدة جديدة شمال أوكرانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مقاطعة زابوروجيه.. طائرات مسيرة من طراز "غيران" الروسية تستهدف محطة فرعية لتوزيع الغاز الأوكراني
![مقاطعة زابوروجيه.. طائرات مسيرة من طراز "غيران" الروسية تستهدف محطة فرعية لتوزيع الغاز الأوكراني]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
لافروف: منفتحون على التفاوض حول أوكرانيا ونحذر من أي خطط توسعية بمنطقة المصالح الحيوية الروسية
![لافروف: منفتحون على التفاوض حول أوكرانيا ونحذر من أي خطط توسعية بمنطقة المصالح الحيوية الروسية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
روسيا.. مقتل شخص وإصابة آخر بهجوم مسيرة أوكرانية
![روسيا.. مقتل شخص وإصابة آخر بهجوم مسيرة أوكرانية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الخارجية الأوكرانية: زيلينسكي لن يتوجه إلى بولندا لتجنب فضائح
![الخارجية الأوكرانية: زيلينسكي لن يتوجه إلى بولندا لتجنب فضائح]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
توسك: مؤتمر أوكرانيا سيكون أكثر جدوى بدون زيلينسكي
![توسك: مؤتمر أوكرانيا سيكون أكثر جدوى بدون زيلينسكي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ريابكوف: مواجهة مباشرة مع الغرب ستقود إلى عواقب كارثية وروسيا ستتخذ إجراءات مضادة في بحر البلطيق
![ريابكوف: مواجهة مباشرة مع الغرب ستقود إلى عواقب كارثية وروسيا ستتخذ إجراءات مضادة في بحر البلطيق]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![العملية العسكرية الروسية في أوكرانيا]() العملية العسكرية الروسية في أوكرانيا
العملية العسكرية الروسية في أوكرانيا
-
![فيديوهات]()
فيديوهات
RT STORIES
الولايات المتحدة.. رياح عاتية تلحق أضرارا واسعة في ولاية إنديانا
![الولايات المتحدة.. رياح عاتية تلحق أضرارا واسعة في ولاية إنديانا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الصين.. شركة "ديب روبوتيكس" الصينية تكشف عن كلب آلي لمكافحة الحرائق
![الصين.. شركة "ديب روبوتيكس" الصينية تكشف عن كلب آلي لمكافحة الحرائق]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![فيديوهات]() فيديوهات
فيديوهات
-
![بعد رفع العقوبات الرياضية.. اعتراض روماني على عودة الرموز الروسية في كأس العالم للجمباز]()
بعد رفع العقوبات الرياضية.. اعتراض روماني على عودة الرموز الروسية في كأس العالم للجمباز
RT STORIES
بعد رفع العقوبات الرياضية.. اعتراض روماني على عودة الرموز الروسية في كأس العالم للجمباز
![بعد رفع العقوبات الرياضية.. اعتراض روماني على عودة الرموز الروسية في كأس العالم للجمباز]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More































































مشكلة "الثقة المفرطة" في الذكاء الاصطناعي تقترب من الحل
قد يكون الذكاء الاصطناعي، بما يملكه من مخزون هائل من المعرفة، مفيدا للغاية، إلا أن له عيبا واحدا قد يحدّ من مزاياه، وهو الثقة المفرطة في الإجابة.

فأي إجابة يقدمها، سواء كانت مبنية على استدلال مدروس أو مجرد تخمين، يطرحها بالقدر نفسه من الثقة.
واكتشف باحثون في مختبر علوم الحاسوب والذكاء الاصطناعي بمعهد ماساتشوستس للتكنولوجيا أن أصل هذه الثقة المفرطة يعود إلى خلل محدد في طريقة تدريب النماذج، وقد طوروا أسلوبا جديدا يهدف إلى معالجة هذا الخلل دون التأثير على دقة الأداء.
وتُعرف هذه الطريقة باسم RLCR (التعلم المعزز باستخدام مكافآت المعايرة)، وقد وُصفت في بحث منشور على منصة arXiv، ومن المقرر تقديمه في المؤتمر الدولي للتعلم الآلي ICLR 2026 في ريو دي جانيرو. وتعتمد هذه المنهجية على تدريب النماذج اللغوية على تقديم إجابات مرفقة بتقدير لدرجة الثقة، أي أن النموذج لا يكتفي بالإجابة، بل يعبّر أيضا عن مستوى عدم يقينه.

ميتا تطلق أداة جديدة تتيح للآباء مراقبة محادثات أطفالهم مع الذكاء الاصطناعي
ما المشكلة؟
تقوم أساليب التعلم المعزز المستخدمة في أحدث نماذج التفكير الاصطناعي على مكافأة الإجابة الصحيحة ومعاقبة الإجابة الخاطئة، دون التمييز بين طريقة الوصول إلى النتيجة. وبالتالي، يحصل النموذج الذي يصل إلى الإجابة الصحيحة عبر استنتاج منطقي، على نفس المكافأة التي يحصل عليها نموذج آخر وصل إليها عن طريق التخمين.
ومع مرور الوقت، يؤدي ذلك إلى ترسيخ سلوك لدى النماذج يجعلها تميل إلى تقديم إجابات واثقة حتى في الحالات التي تفتقر فيها إلى الأدلة الكافية.
وتترتب على هذه الثقة المفرطة آثار سلبية، خاصة عند استخدام هذه النماذج في مجالات حساسة مثل الطب أو القانون أو التمويل، حيث تعتمد القرارات البشرية على مخرجات الذكاء الاصطناعي. فالنموذج الذي يعبر عن ثقة عالية غير دقيقة قد يكون أكثر خطورة من نموذج يخطئ بوضوح، لأن المستخدم قد لا يدرك ضرورة التحقق من الإجابة.
ويشرح طالب الدراسات العليا في معهد ماساتشوستس للتكنولوجيا وأحد مؤلفي الدراسة، ميهول داماني، قائلا:
"إن أساليب التدريب التقليدية بسيطة وفعالة، لكنها لا تشجع النموذج على التعبير عن عدم اليقين أو قول (لا أعرف)، لذلك يتعلم النموذج بطبيعته أن يخمّن عندما لا يكون واثقا".
ما الحل؟
تعالج طريقة RLCR هذه المشكلة بإضافة عنصر واحد إلى دالة المكافأة، وهو مقياس "براير" (Brier score)، المستخدم لقياس مدى تطابق ثقة النموذج مع دقته الفعلية. خلال التدريب، تتعلم النماذج تقييم كل من الإجابة وعدم يقينها في الوقت نفسه، بحيث تقدم الجواب مع تقدير لمستوى الثقة.
وبذلك تتم معاقبة كل من الإجابات الخاطئة ذات الثقة المبالغ فيها، والإجابات الصحيحة المصحوبة بعدم ثقة غير مبررة، مما يساعد على تحقيق توازن أفضل بين الدقة والتعبير الواقعي عن الثقة.
المصدر: Naukatv.ru
إقرأ المزيد

OpenAI تحل لغز الهوس الغريب لتطبيق ChatGPT بالمخلوق اﻷسطوري "غولبن"
تمكنت شركة OpenAI من حل لغز تسبب في تحول روبوت الدردشة الشهير ChatGPT إلى كائن مهووس بالمخلوقات الأسطورية، وخصوصا "الغولبن" (goblins).

لا أثق به ثقة عمياء.. مدفيديف يتحدث عن التحدي الأكبر في مواجهة الذكاء الاصطناعي
كشف نائب رئيس مجلس الأمن الروسي دميتري مدفيديف أنه يستخدم برمجيات الذكاء الاصطناعي في عمله اليومي، لكنه لا يثق بها ثقة عمياء.

DeepSeek تطلق ذكاء اصطناعيا جديدا يتفوق على معظم النماذج مفتوحة المصدر
أطلقت DeepSeek الصينية أحدث نماذجها في مجال الذكاء الاصطناعي، الإصدار الرابع (V4)، في خطوة جديدة تعكس تصاعد المنافسة العالمية في هذا القطاع.

عطل أم تصرف عدواني؟.. روبوت يفلت من السيطرة في مهرجان صيني (فيديو)
أثارت حادثة غريبة خلال مهرجان في الصين جدلا كبيرا حول سلامة الروبوتات المتقدمة، بعد أن ظهر روبوت شبيه بالإنسان وهو يتحرك بشكل غير متوقع، ما أثار صدمة الحاضرين.

DeepSeek تحذر المستخدمين من انتشار معلومات كاذبة عنها
حذّرت شركة DeepSeek الصينية مستخدمي الإنترنت من انتشار معلومات كاذبة عنها، وأوصت باستخدام مواقعها الرسمية.






























































































التعليقات